为什么气象上会用到超算, 甚至要用云计算?
发布时间:2016年12月20日
来源:气象知识
分享:

我们眼中的大气,除了打雷下雨之外,平时看起来真是风平浪静,波澜不惊。
但是,就像河里存在暗涌一样,大气无时无刻不在运动变化中。那么它们哪来的动力东蹿西跳呢?这当然要归功于万丈光芒无所不“能”的太阳。
阳光普照大地,温暖的地表带给每个大气分子以活力,分分钟欢乐大party。不仅自己high,而且还成群结队地抱团以产生湍流,就像梵高的《星空》一样壮观。
温度对于单个分子来说是没有意义的,所以抱团high才能产生温度。
孤单的时候就和身边的小伙伴碰撞出火花,发生化学反应。势单力薄的时候就吸引小水汽来壮大自己。
当然狂欢久了也要歇歇,要是用尽洪荒之力就歇菜了。高处的哥们儿兴致低了慢慢下落,奈何被太阳君加热的温暖的地表又一次把它们撵回高处,而冷空气在偏僻角落静静地看着远处的繁华,一有机会趁虚流入。这样一来一回的较量,风就形成了。
当high到一定的高度,小水汽就开始凝结,从宏观来看,好大一朵棉花糖状的云。
所以,大气无时无刻都在进行动力、热力、微物理、化学的过程。
回到题目中的问题,为什么要用到超算?
用到这类工具意味着计算量异常巨大,为什么?有哪些计算量?需要进行怎样的运算?
以大家熟悉的预报为例,怎样得出预报结果?
除了运用理论和经验对高空和地面形势作分析进而对未来天气进行预判,还需要借助“数值天气预报”。
说起“数值天气预报”,大家都听说过大学竞赛里的数学建模吧,同为一个道理。
上面所说的空气分子狂欢大party并不是毫无章法无规律可言,科学家们经过千锤百炼,总结出这些规律,得出六个大气运动方程组。大气中的风场、气压场、密度场和温度场的时空变化都可以用这组方程加以描述。
方程出来就能精确描述大气运动了吗?不,因为这里包含了理想条件下的情况,就像真空和非真空,光滑和有摩擦一样。而且在数学上这些方程的解析解极难获得,所以需要在时间和空间上离散化(比如差分)之后求解,这样就造成了可解析与不可解析之间的差异。
由于这些过程通常都无法解析,它们需要按照与可解析尺度的相互作用被“参数化”。
什么是参数化?其实,早在初中物理课本上就出现过参数化的例子了,如摩擦系数μ。把手放在桌面上往前移,可以感受到桌面的粗糙质感。如何描述颗粒度不均一的表面?引入一个摩擦系数μ,就代表了整个桌面的粗糙程度。当然,这只是个类比。
为何看似简单的过程还要用到超算?
很简单吗?真的很简单吗?
比如,欧洲中期天气预报中心的预报模式分辨率为0.125°×0.125°(间距约15千米),垂直方向从地面到中间层(地面以上约80千米)91层(假设),使用从数小时到数天的时间窗,这样就形成一个四维空间。
每一水平层有两百万个格点,以10分钟的时间步长进行10天的预报,即1440个时间步(一天有24小时,1440分钟,86400秒。自己算吧,笔者脑仁疼)。相应的集合预报有50个集合成员,生成15~30天的预报,有着30~60千米的水平分辨率和30分钟的时间步长。这样每天两次,有大约四百亿个格点柱的运算在2.5小时内实时运算完毕。这样庞大的运算量天晓得除了超算设备还能用什么!
对欧洲中期天气预报中心这样的数值天气预报中心来说,可负担的能源消耗的上限大约是两千万伏安。此外,长时间的大矩阵的运算,速度不会一直保持高水平,肯定越来越慢,对硬件也是一种损耗和考验。
但是有些运动尺度小于15千米(如对流,湍流),模式的动力核心体现不出这种变化,而这些变化也会影响格点上物理量的值。怎么办?引入参数化方案。大部分的物理过程参数化的代码长度,都要比动力核心的长度要长。
不知道过去,怎么预测未来。所以,模拟过程中初始条件的设定是至关重要的啦。
什么是初始条件?简单说就是观测数据。
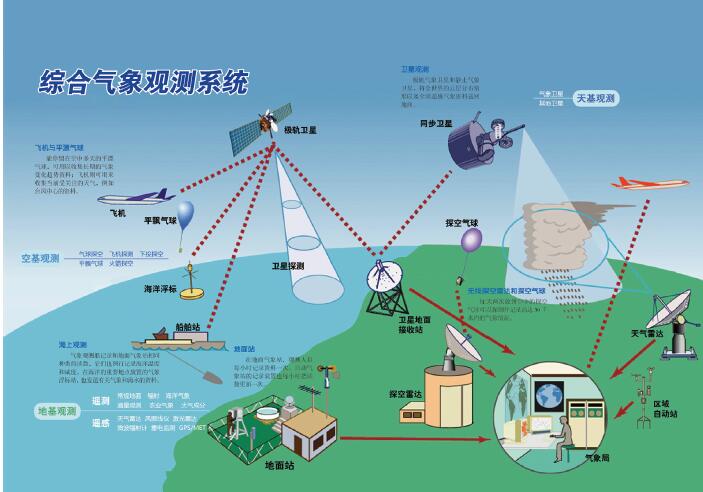
卫星、船舶、雷达、无人机……平时看起来简简单单的预报要动用这么多设备,不仅观测温、湿、风、气压能见度这些常规数据,还要观测云顶状况、臭氧、太阳辐射、海表温度等等。卫星和雷达这两类仪器每天都能产生一千亿字节数量级的数据,这些数据需要在几个小时内下行、预处理并分发以供预报系统使用。当然,这还只是初始化而已。
这么多设备输出的资料如何统一?而且观测站并不是严格和均匀地分布在格点上(比如中国的站点就是东多西少),这时候就需要资料同化来计算以获得格点上的近似气象资料。
什么是资料同化?通俗来说,就是把不同来源的数据通过一系列的处理、调整,最终能够综合进行运用的一个过程。
比如西藏的观测站点少,要想知道西藏在均匀格点上的温度分布情况,该如何做?最先想到的是插值。插值就是在离散数据的基础上补插连续函数,使这条连续曲线通过全部给定的离散数据点。利用它可通过函数在有限个点处的取值状况,估算出函数在其他点处的近似值。
在欧洲中期天气预报中心,资料同化在多个阶段中进行模式积分,总计要在12小时的同化时间窗内对6亿5千万的格点进行数百次迭代运算。与此同时,还有大约1千万个辐射运算将超过60个仪器的卫星观测数据和预报模式加以比较。
随着演变时间的推移,数据的计算量呈指数增长,但是其准确率是下降的。就像“蝴蝶效应”一样,在初始条件中加一个微小扰动,就会带来完全不同的结果。
未来天气的预报就像是一个战场,可预报之力与不可预报之力两军对垒。
可预报性的根源在于大气、陆面、植被、海冰和海面的相互作用等。
不可预报性的根源包括小尺度里不稳定性引入的混沌的“噪音”等(遇到“混沌理论”……有些事情真是太复杂)。
偏微分方程+浮点数计算+水平方向n个格点+垂直方向n层+时间步长限制+参数化方案+…… 超算已经累倒在路上,宝宝心里苦……计算还要考虑到时效性问题,今天刚刚算出来结果可是太阳已经下山了,黄花菜都凉了,谁看?
来看看耗时又耗巨大资源的家伙到底长啥样:
没错,就是它:
未来还是光明的,比如上面提到的水平分辨率是15千米,要是达到1千米呢?有着此等分辨率,舍我其谁,模拟效果将大大提高。
最后给大家开个脑洞,设想在不久的将来你的手机变成一台可以用来监测气象要素的设备,那么观测网就能变成高密度的了,虽然精度可能不足但是采样率大大提高。每个人都是一个小小监测仪,这数据覆盖率,真是相当可观。
